
By David Nussbaum
Two wonderful blog posts this week that you won’t want to miss if you’re interested in questions of statistical power in personality and social psychology. In the first, Simine Vazire (@siminevazire) argues that sample sizes can’t be too large:
you can’t have too large a sample. there is no ‘double-edged sword’. there are no downsides to a large sample. more evidence is always better, and larger samples = more evidence.
this seems very obvious but i’ve seen at least three different editors criticize manuscripts for having samples that are too big. so i want to be very clear: there is no such thing as a sample that is too big. calling a sample too big is like calling a a grizzly bear too cute. it makes no sense.
(Note: The link at the end there is to a post in a similar vein by Joe Simmons (@jpsimmon) at the datacolada blog.)
Several people on twitter were quick to point out that there are costs to collecting more data, which is certainly true, but Simine had already anticipated that, as Sanjay Srivastava (@hardsci) points out:
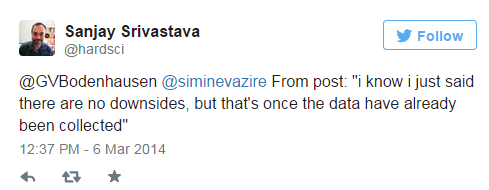
The post goes on to make some thoughtful recommendations about how researchers really can improve things by slowing down. Go read the whole thing, and make sure to follow Simine on twitter and her new blog “sometimes i’m wrong.” And check out Michael Kraus’ (@mwkraus) related thoughts:
The second post, by Will Gervais, who also just started a new blog (subliminal message: the norm is to blog, everyone is doing it, so should you. If you don’t want to start your own blog, contact me and I’ll post your writing on this site.), echos these same sentiments: we need more power, otherwise we’re dramatically inflating our false positive rates. Gervais summarizes Uri Simonsohn’s (@uri_sohn) recent talk at SPSP and calls for a rethinking of the incentive structure that pushes researchers towards running many small studies rather than fewer big ones that are likely to be reliable.
[Simonsohn’s] recommendation mirrors pretty much exactly what I’ve been doing for the past couple of years (damn, I got scooped again!). Instead of trying to predict your effect size a priori, why not pick what effect size you would find meaningful? Brilliant! Some effects are only meaningful if they are very large. Other effects can be meaningful even when small. Pick what effect size you think would be relevant, then go with an appropriate sample size for that effect.
If the results are significant…yay! If the results are not significant…also yay! That second bit sounds counterintuitive, but I’ll stand by it. If you said at the outset “I would care about this effect if it was at least X big” and your results are not significant, you can move on from that project because–by your own definition–the effect is probably either nonexistent, or too small for you to care about. After a couple of years of this, it is lovely being able to drop ideas in a more conclusive manner. And you can only do this with an adequately powered study.
Read the whole thing here — and leave your thoughts in the comments section below.

Do People Cheat More When They Feel Powerful or Powerless?

Why People Aggress
